Links:
Can be used to handle vanishing and exploding gradients problem and Overfitting problems within Neural network.
First note: Normalisation vs Standardisation
How does Batch normalisation work?
Batch normalisation works by first standardising the inputs, then scales linearly - coefficients determined through training. This occurs between each layer.
Outcomes of this process:
- epochs take longer, but less epochs are required.
Benefits:
- Batch normalisation occurs at each layer, so do not need separate normalisation step for input data.
- What about bias? We do not need bias in BN.
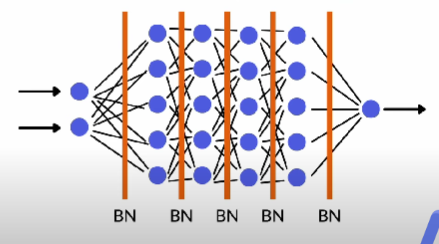
Example:
import tensorflow as tf
from tensorflow import keras
import matplotlib.pyplot as plt
mnist = keras.datasets.mnist
(X_train_full, y_train_full) , (X_test, y_test) = mnist.load_data()
plt.imshow(X_train_full[12], cmap=plt.get_cmap('gray' ))
X_valid, X_train = X_train_full[:5000] / 255, X_train_full[5000:]/255
y_valid, y_train = y_train_full[:5000], y_train_full[5000:]
X test = x test/255
model = keras.models.Sequential([
keras.layers.Flatten(input_shape=[28,28]),
keras.layers.Dense(300, activation = "relu"),
keras.layers.Dense(100, activation = "relu"),
keras.layers.Dense(10, activation = "softmax")])
Introducing BN into this model.
Do you put BN before or after a activation function? Author of Paper suggests before.
# Dont need as have BN now
# X valid, X train = X_train_full[ :5000] / 255, X_train_full[5000:]/255
# y_valid, y_train = y_train_full[:5000], y_train_full[5000:]
# X test = X test/255
model = keras.models.Sequential ([
keras.layers.Flatten(input_shape=[28,28]),
keras.layers.BatchNormalization(), # normalisation layer.
keras.layers.Dense(300,use_bias=False),
keras.layers.BatchNormalization(),
keras.layers.Activation('relu'),
keras.layers.Dense(100,use_bias=False), I
keras.layers.BatchNormalization(),
keras.layers.Activation('relu'),
keras.layers.Dense(10, activation = "softmax")
])