Supervised learning is a type of machine learning where an algorithm learns from labeled data to make predictions or decisions.
In supervised learning, the training data consists of input-output pairs, where each input (features) is associated with a known output (label or target).
The algorithm’s goal is to learn a mapping from the input to the output so that it can predict the output for new, unseen data.
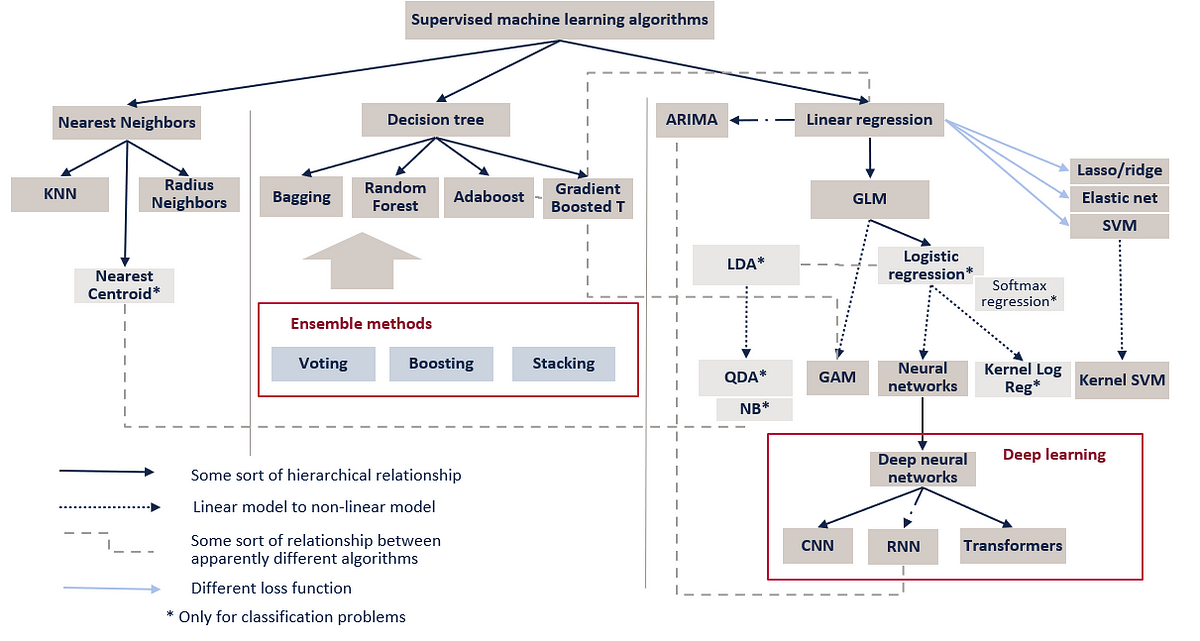
Examples of Supervised Machine Learning Algorithms:
- K-nearest neighbours (KNN)
- Naive Bayes Classifier
- Decision Tree
- Linear Regression
- Support Vector Machines (SVM)
Key Characteristics of Supervised Learning:
- Labeled Data: The training dataset contains both the input data and the corresponding correct outputs (labels).
- Training Phase: The model is trained using this labeled data to minimize errors in predicting the output.
- Prediction: After training, the model can predict the output (label) for new data based on what it learned.
Types of Supervised Learning Algorithms:
Supervised learning algorithms learn from labeled data, where each example is associated with a target label.
Labelled data can look like the following:
| Email Content | Label |
|---|---|
| ”Congratulations! You won a free iPhone.” | Spam |
| ”Meeting scheduled for 2 PM tomorrow.” | Not Spam |
| ”Special offer: Buy 1 get 1 free!” | Spam |
| ”Please find the attached report.” | Not Spam |
| Labelling can be expensive and time consuming. |
- Classification: Predicts discrete labels (e.g., categories).
- Regression: Predicts continuous values.
Example:
In a house price prediction task:
- The input features could be the size of the house, number of rooms, and location.
- The output (label) would be the price of the house.
The model is trained on a dataset where the house prices are known (labeled data), and it learns to predict the price for new houses.
Code implementation
That is there is a y_train, then uses to get y_pred (from X_test) and compare against y_test.