Deep Q-Learning is a type of reinforcement learning algorithm that combines Q-Learning with Neural network. Necessary when Q-Table grows too large.
Updates the weights in the model.
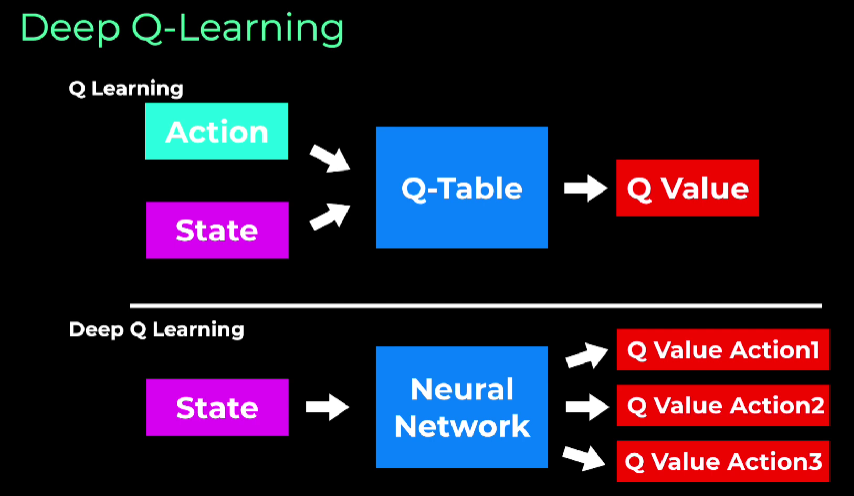
Key Concepts
Target Network
- Purpose: The target network is used to stabilize the training process in Deep Q-Learning.
- When is it needed?: It is needed when updating the Q-values to prevent oscillations and divergence during training.
- How it works: The target network is a copy of the main Q-network and is used to generate target Q-values. It is updated less frequently than the main network, often using a technique called a “soft update,” where the target network is slowly adjusted towards the main network over time.
Experience Replay
- Purpose: Experience replay is used to break the correlation between consecutive experiences, which can lead to inefficient learning and instability.
- Issue it resolves: When an agent learns from sequential experiences, the strong correlations between them can cause problems such as oscillations and instability in learning.
- How it works:
- Experiences (state, action, reward, next state) are stored in a memory buffer.
- During training, random mini-batches of experiences are sampled from this buffer to update the network.
- This random sampling helps to generate uncorrelated experiences, improving stability and efficiency.
- It also allows the agent to reuse experiences for multiple updates, increasing data efficiency.