Support Vector Machines (SVM) are a type of supervised learning algorithm primarily used for Classification tasks, though they can also be adapted for regression.
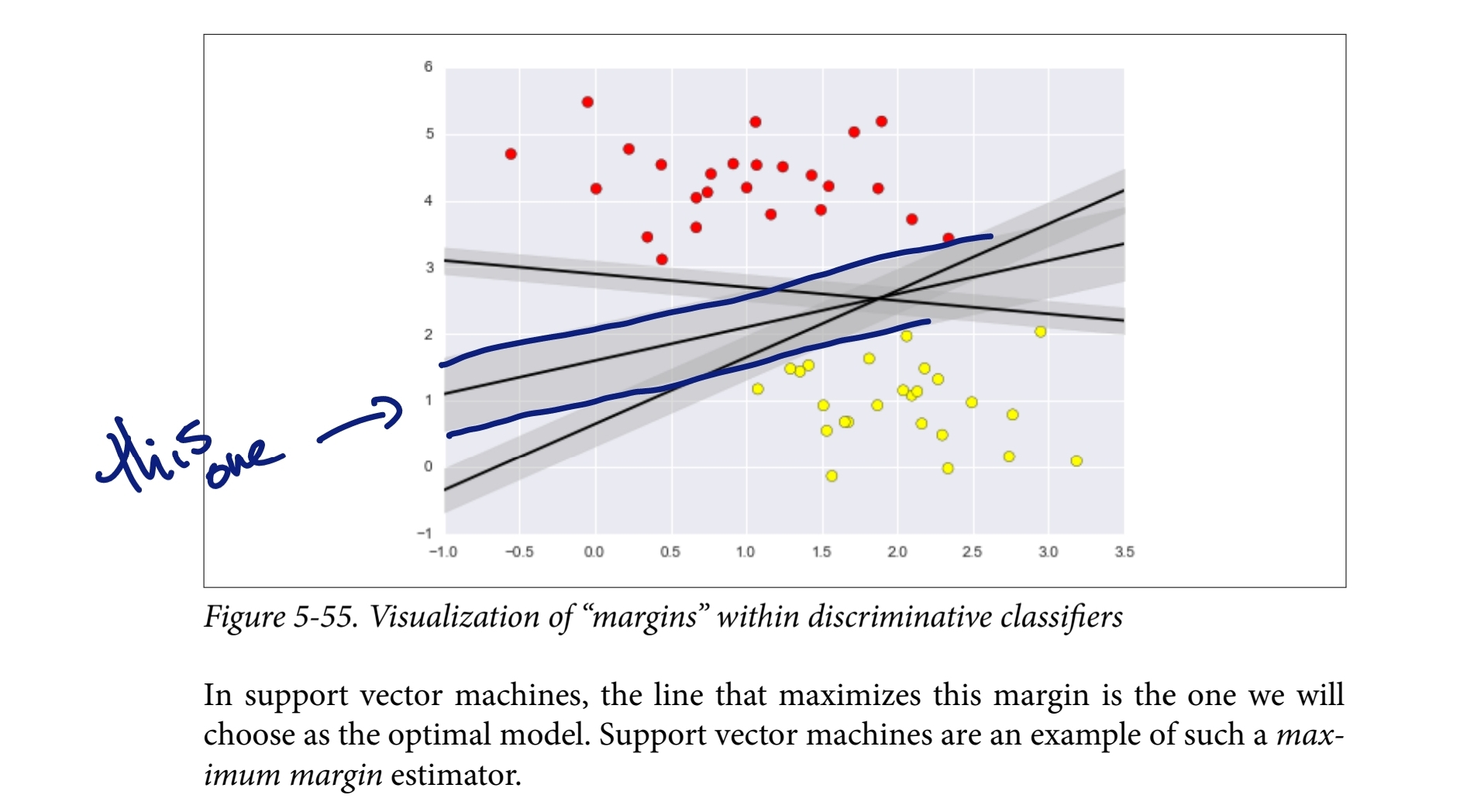
The main idea is to find an optimal hyperplane that divides data into different classes by maximizing the margin between them.
The support vectors are the data points closest to the hyperplane, influencing its position and orientation.
Key Features
- Hyperplane: Finds a hyperplane that maximizes the margin between classes.
- High-Dimensional Spaces: Robust in high-dimensional spaces, such as image and text classification.
Advantages
- Highly effective for high-dimensional data (datasets with many features).
- Useful for classification tasks where a clear margin of separation exists between classes.
Disadvantages
- Can be computationally expensive for large datasets and sensitive to the choice of hyperparameters.
- Performance is highly dependent on the Kernelling choice, requiring careful tuning.
Visualisation: https://dash.gallery/dash-svm/
How SVM Works
In ML_Tools see: SVM_Example.py
- Initial Space: Start in the low-dimensional space, where the data may not be linearly separable.
- Kernel Function: Use a Kernelling function to move the data into a higher dimension where separation is clearer.
- Hyperplane Placement: Place hyperplanes (decision boundaries) between the data clusters to classify the data.
Margins
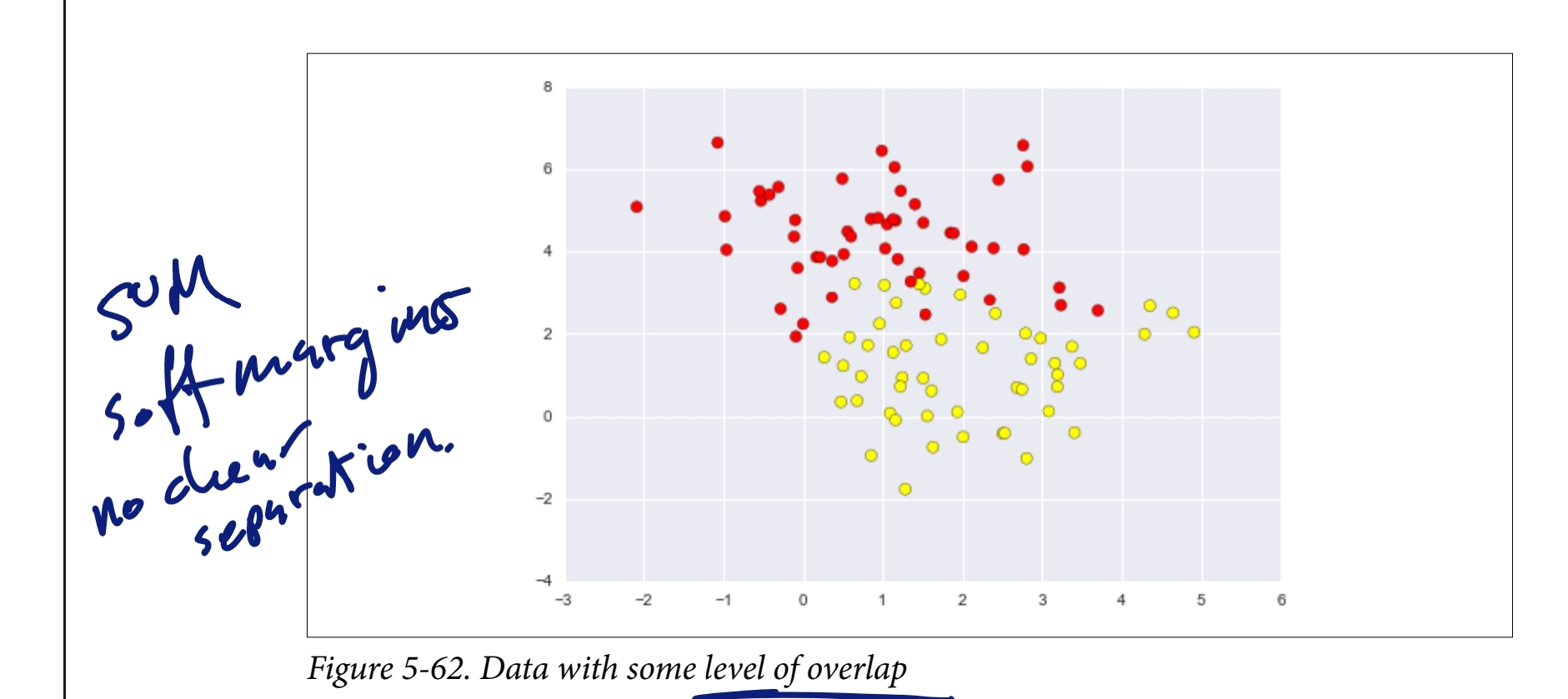
- Outliers and Soft Margins: SVM allows for some miscalculations or errors in classification to handle outliers. This is part of the Bias and variance tradeoff, where the model is allowed to make a few mistakes to improve generalization.
- Soft Margins: Allow some data points to be within the margin or even on the wrong side of the hyperplane, enabling SVM to handle imperfect separations.