Lambda architecture is a data-processing architecture designed to handle massive quantities of data by taking advantage of both batch and stream-processing methods. Data Streaming
This approach to architecture attempts to balance latency, throughput, and fault tolerance using batch processing to provide comprehensive and accurate views of batch data, while simultaneously using real-time stream processing to provide views of online data.
The two view outputs may be joined before the presentation. The rise of lambda architecture is correlated with the growth of big data, real-time analytics, and the drive to mitigate the latencies of MapReduce.
Lambda architecture is a design pattern for processing large volumes of data by combining both batch and stream processing methods. It aims to provide a comprehensive and efficient way to handle big data by addressing the needs for low-latency data processing, high throughput, and fault tolerance.
Lambda architecture is particularly useful in scenarios where both historical and real-time data insights are crucial, such as in financial services, telecommunications, and online retail. It allows organizations to leverage the strengths of both batch and stream processing to meet diverse data processing needs.
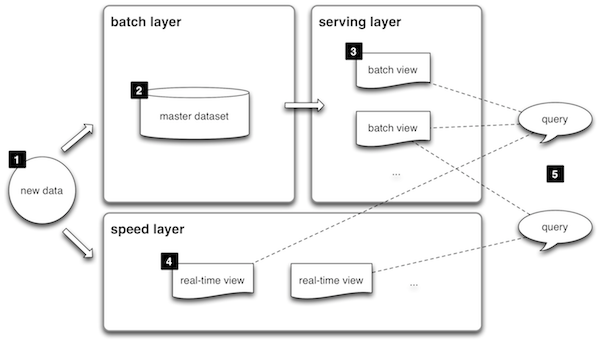
How it works:
- All data entering the system is dispatched to both the batch layer and the speed layer for processing.
- The batch layer has two functions: (i) managing the master dataset (an immutable, append-only set of raw data), and (ii) to pre-compute the batch views.
- The serving layer indexes the batch views so that they can be queried in low-latency, ad-hoc way.
- The speed layer compensates for the high latency of updates to the serving layer and deals with recent data only.
- Any incoming query can be answered by merging results from batch views and real-time views.
Components of Lambda Architecture
-
Batch Layer:
- Purpose: To process large sets of historical data in batches.
- Functionality: It computes results from all available data, ensuring accuracy and completeness.
- Tools: Often uses distributed processing frameworks like Hadoop or Spark for batch processing.
- Output: Produces a batch view, which is a complete and accurate dataset that can be queried.
-
Speed Layer:
- Purpose: To process real-time data streams with low latency.
- Functionality: It provides immediate insights by processing data as it arrives.
- Tools: Utilizes stream processing frameworks like Apache Storm, Apache Flink, or Spark Streaming.
- Output: Generates a real-time view that reflects the most recent data.
-
Serving Layer:
- Purpose: To merge and serve the results from both the batch and speed layers.
- Functionality: It combines the batch view and real-time view to provide a unified, queryable dataset.
- Tools: Databases or data stores optimized for fast reads, such as Cassandra or HBase, are often used.
How Lambda Architecture Works
- Data Ingestion: Data is ingested into both the batch and speed layers simultaneously.
- Batch Processing: The batch layer processes data in large volumes, typically with higher latency, to ensure accuracy and completeness.
- Stream Processing: The speed layer processes data in real-time, providing low-latency updates.
- Data Serving: The serving layer combines outputs from both layers, allowing users to query the most up-to-date and accurate data.
Benefits of Lambda Architecture
- Fault Tolerance: By separating batch and real-time processing, the architecture can handle failures more gracefully.
- Scalability: It can scale to handle large volumes of data by leveraging distributed processing frameworks.
- Flexibility: Supports both historical and real-time data processing, making it suitable for a wide range of applications.
Challenges
- Complexity: Maintaining two separate processing paths (batch and speed) can increase system complexity.
- Data Consistency: Ensuring consistency between batch and real-time views can be challenging.
- Maintenance: Requires more effort to maintain and update due to its dual-layer nature.