What is LSTM
LSTM (Long Short-Term Memory) networks are a specialized type of Recurrent Neural Network (RNN) designed to overcome the vanishing and exploding gradients problem that affects traditional Recurrent Neural Networks.
LSTMs address this challenge through their unique architecture.
Used for tasks that require the retention of information over time, and problems involving sequential data.
The key strength of LSTMs is their ability to manage long-term dependencies using their gating mechanisms.
Key Components of LSTM Networks:
Resources: Understanding LSTM Networks
input, output, cell state , conveyer belt
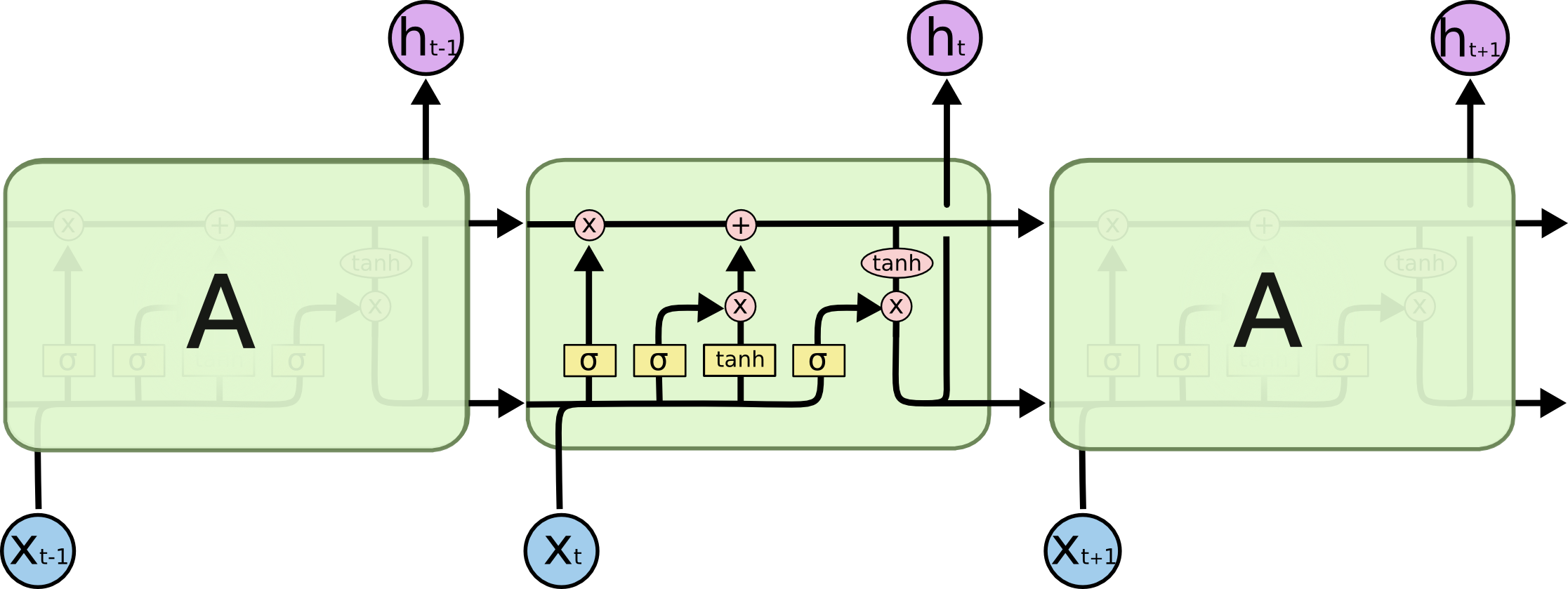
Memory Cell:
- The core of an LSTM network is the memory cell, which maintains information over long time intervals. This cell helps store, forget, or pass on information from previous time steps.
Gates:
- Input Gate: Controls how much of the input should be allowed into the memory cell.
- Forget Gate: Determines which information should be discarded from the memory cell.
- Output Gate: Controls what part of the cell’s memory should be output as the hidden state for the current time step.
These gates are regulated by sigmoid activation, which output values between 0 and 1, acting like a filter to determine the amount of information that should pass through. This gate mechanism allows the LSTM network to maintain a balance between retaining relevant data and discarding unnecessary information over time.
Why is LSTM less favourable over using transformers
Summary
Long Short-Term Memory (LSTM) networks, a type of Recurrent Neural Network (Recurrent Neural Networks), are less favorable than Transformer for many modern tasks, especially in Natural Language Processing (NLP). LSTMs process sequences of data one step at a time, making them inherently sequential and difficult to parallelize. Transformers, on the other hand, leverage a self-attention mechanism that allows them to process entire sequences simultaneously, leading to faster training and the ability to capture long-range dependencies more effectively.
Mathematically, LSTM’s sequential nature leads to slower computations, while the Transformer’s attention mechanism computes relationships between all tokens in a sequence, allowing better scalability and performance for tasks like translation, summarization, and language modeling.
Breakdown
Key Components:
- Sequential Processing in LSTM: Each time step relies on the previous one, creating a bottleneck for long sequences.
- Self-Attention Mechanism in Transformers: Allows simultaneous processing of all elements in a sequence.
- Parallelization: Transformers leverage parallel computing more effectively due to non-sequential data processing.
- Positional Encoding: Used by Transformers to retain the order of the sequence, overcoming the need for explicit recurrence.
Important
- LSTMs are slower in training due to their sequential nature, as calculations depend on previous states.
- Transformers efficiently handle long-range dependencies using self-attention, which calculates the relationships between tokens directly without needing previous time steps.
Attention
- LSTMs suffer from vanishing/exploding gradient issues, especially in long sequences, limiting their effectiveness for long-term dependencies.
- Transformers require more data and computational power to train, which can be a limitation in resource-constrained environments.
Example
In a language translation task, LSTMs process words sequentially, making them less efficient in handling long sentences. In contrast, a Transformer can analyze the entire sentence at once, using self-attention to determine relationships between all words, leading to faster and more accurate translations.
Follow
- How does the attention mechanism in Transformers improve the model’s ability to capture long-range dependencies compared to LSTM’s cell structure?
- In what cases might LSTM still be a better option over Transformers, despite their limitations?
Related
- Attention mechanism in deep learning
- BERT (Bidirectional Encoder Representations from Transformers)
- GRU (Gated Recurrent Unit) as an alternative to LSTM
Example Workflow in Python using Keras:
In this example, we define a simple LSTM model in Keras for a time series forecasting task. The model processes sequences with 1000 time steps, and the LSTM layer has 50 units, followed by a fully connected (Dense) layer for the final prediction.
import numpy as np
from keras.models import Sequential
from keras.layers import LSTM, Dense
# Sample data: time series with 1000 timesteps and 1 feature
time_steps = 1000
features = 1
X_train = np.random.rand(1000, time_steps, features)
y_train = np.random.rand(1000)
# Define LSTM model
model = Sequential()
model.add(LSTM(50, activation='tanh', return_sequences=False, input_shape=(time_steps, features)))
model.add(Dense(1)) # Output layer for regression tasks
model.compile(optimizer='adam', loss='mse')
# Train the model
model.fit(X_train, y_train, epochs=10, batch_size=64)notes
LSTM How to implement LSTM with PyTorch? https://lightning.ai/lightning-ai/studios/statquest-long-short-term-memory-lstm-with-pytorch-lightning?view=public§ion=all without lightning - there is a script there