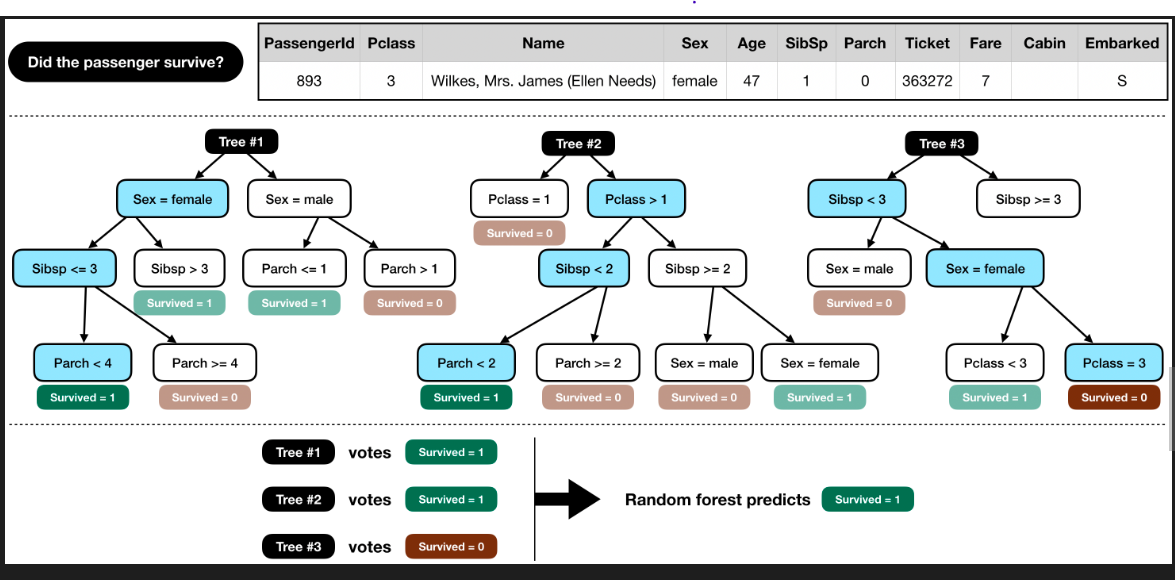
A Random Forest is an Model Ensemble method that combines many Decision Trees to improve accuracy and generalisation.
How does Random Forest work?
- Each tree is trained on a random bootstrap sample of the training data (bagging).
- At each split, the tree considers only a random subset of features (commonly features if is the total number).
- The final prediction is obtained by majority vote (classification) or averaging (regression).
This randomness reduces correlation between trees, making the overall model more robust (generalize).
Key properties:
- Can handle regression, classification, dimensionality reduction, and missing values.
- Flexible, robust, and resistant to overfitting compared to a single Decision Tree.
- Works well with high-dimensional data.
Hyperparameters to tune:
n_estimators: number of trees.max_depth: maximum depth of each tree.max_features: number of features considered at each split (default for classification).n_jobs: controls parallelism during training (more cores = faster training, but watch out for system slowdown).
Strengths:
- Reduces variance compared to a single tree.
- Handles large datasets and mixed feature types well.
- Provides feature importance estimates.
Weaknesses:
- Can still overfit with noisy or very high-dimensional data.
- Less interpretable than a single decision tree.
Evaluation:
- Out-of-bag (OOB) error can be used as an internal validation metric (data not included in bootstrap samples).
- Model performance can be refined by tuning Hyperparameters.
Related: