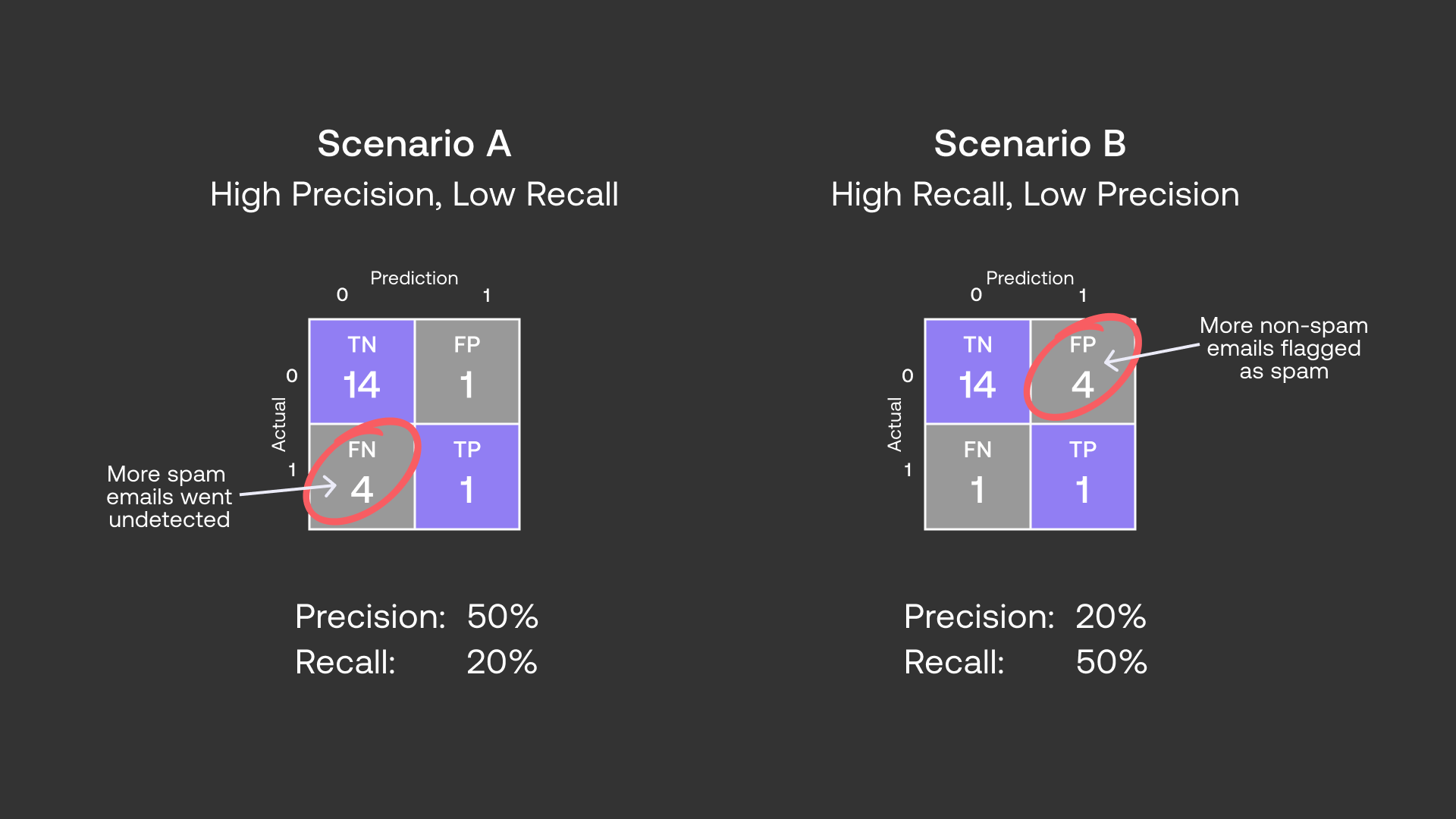
Precision and Recall are two fundamental metrics used to evaluate the performance of a Classification model, particularly in binary classification tasks. They are related through a trade-off: improving one often comes at the expense of the other.
Key Differences:
- Precision focuses on the quality of positive predictions.
- Recall focuses on the ability to identify all relevant positive instances
Trade-off:
- It is challenging to optimize both precision and recall simultaneously. Improving precision by reducing false positives may lead to an increase in false negatives, thereby reducing recall, and vice versa.
- However, it’s important to balance recall with precision. A model with high recall might also have a higher rate of false positives (non-spam emails incorrectly marked as spam), which can lead to important emails being missed.
Task Dependency Example:
- The choice between prioritizing precision or recall is task-dependent. In a spam classification task, it might be more important to avoid moving important emails to the spam folder (high precision) than to occasionally allow spam emails into the inbox (lower recall). Thus, precision is prioritized over recall in this context.