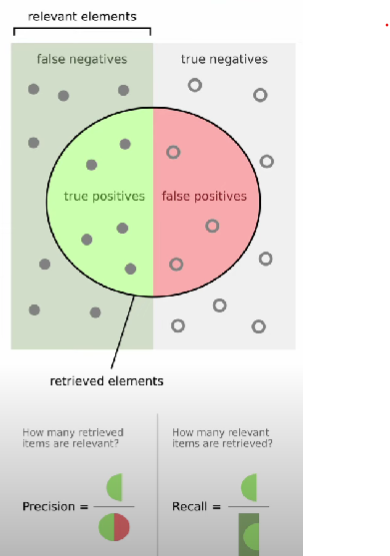
Recall Score is a Evaluation Metrics used to evaluate the performance of a Classification model, focusing on the model’s ability to identify all relevant instances of the positive class.
It answers the question: ==How many relevant items are retrieved?==
High recall means that the model is effective at identifying most of the actual spam emails. This is useful in environments where missing a spam email could lead to security risks such as in corporate email systems.
The formula for recall is:
Importance
- Recall is crucial in scenarios where ==missing a positive instance is costly==, such as in disease screening or fraud detection.
- It helps in understanding how well the model captures all the actual positive instances.
Related Concepts
- Sensitivity (also known as recall or the true positive rate) measures the proportion of actual positives that are correctly identified by the model. It indicates how well the model is at identifying positive instances.