The learning rate is a Hyperparameter in machine learning that determines the step size at which a model's parameters are updated during training. It plays a significant role in the optimization process, particularly in algorithms like Gradient Descent which are used to minimize the Loss function.
Key Points about Learning Rate:
Parameter Updates:
- During training, the model’s parameters (such as weights and biases in neural networks) are adjusted iteratively to minimize the loss function.
- The learning rate controls how much the parameters are changed in response to the estimated error each time the model weights are updated.
Impact on Training/ Convergence
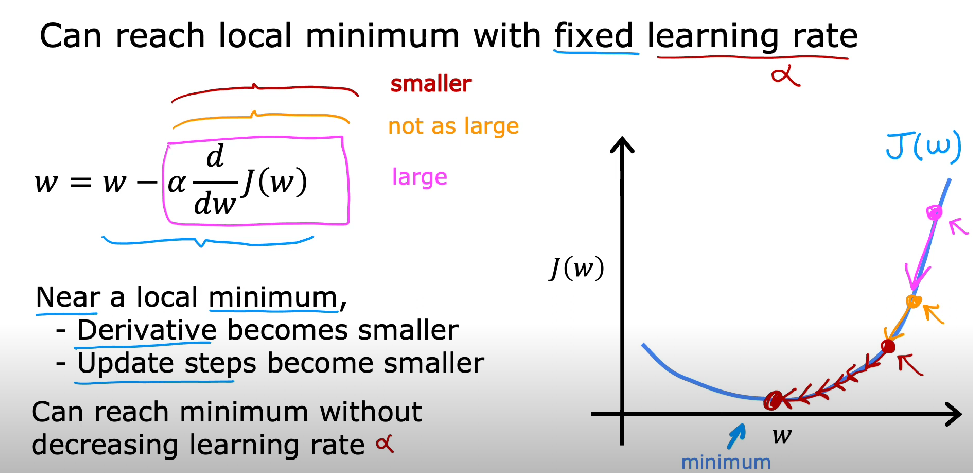
- A high learning rate can lead to faster convergence but risks overshooting the optimal solution, potentially causing the model to diverge.
- A low learning rate ensures more stable and precise convergence but may result in slow training and can get stuck in local minima. A lower learning rate makes the model more robust but requires more iterations to converge.
Tuning:
- The learning rate is a hyperparameter that needs careful tuning. It can be adjusted manually or through automated hyperparameter optimization techniques like Optuna.
- The optimal learning rate depends on various factors, including the dataset, model complexity, and the specific optimization algorithm used.
Practical Considerations:
- It’s common to start with a moderate learning rate and adjust based on the model’s performance during training.
- Techniques like learning rate schedules or adaptive learning rate methods (e.g., Adam Optimizer) can dynamically adjust the learning rate during training to improve convergence.
Learning rate:
- impacts the efficiency of Gradient Descent
- Effects occur if too small (takes long), or too large (over shoots missing the minima).
- What happens if you are at a local minima? Then no change.