Even scaled model cannot cross tthe compute efficent frontier
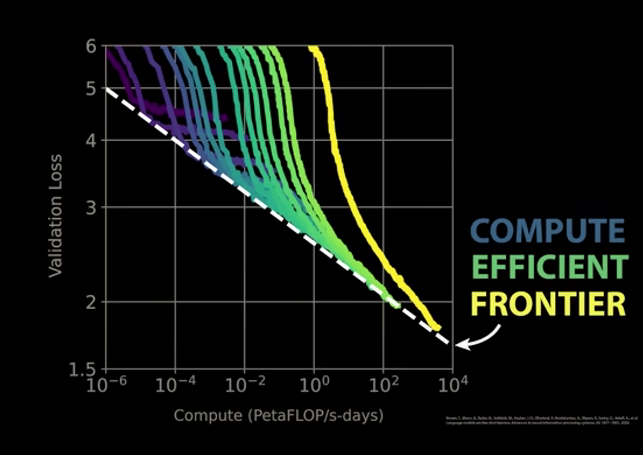
Neural scaling laws. That is error rates scale with compute,model size and dataset size, independant of model aritechture. Can we drive to 0?
Same laws apear in video and image models.
LLMs are auto progressive models.
Theorical results guiding experiemental - saving compute time.
How LLMs work

During training we know next value, hence we have a Loss function to help learning.
L1 - loss functions
Cross Entropy-loss function (uses negative log of probability). Why is cross enropy used over L1?
unabigious next words. Entropy of natural language due to this will LLMs cannot drive Cross entropy loss to zero.
Manifolds?
Example MNIST data set images of number, has high dimesnional dataset space.
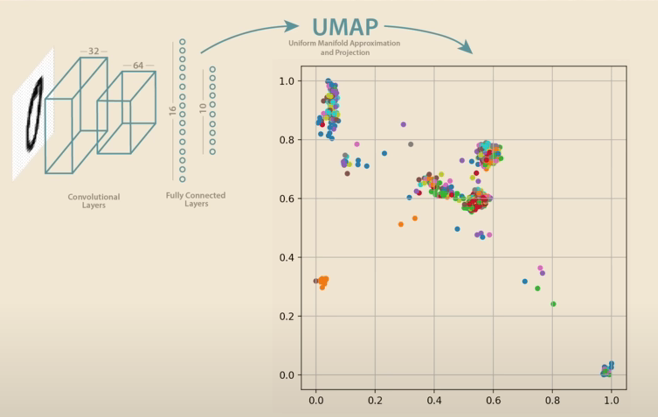
16:03 Simlar concepts group together.
density of manifold average distance between point. or size of neightbourhoods s

Manifold hypothesis (data points in high dim space) and scaling laws
Knowing the manifold will help scaling. This is called
Cross entropy loss should scale wrt manifold.