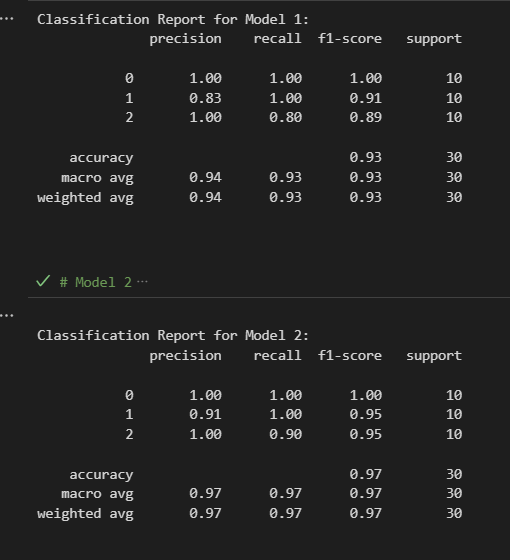
The classification_report function in sklearn.metrics is used to evaluate the performance of a classification model. It provides a summary of key metrics for each class, including precision, recall, F1-score, and support.
Function Signature
sklearn.metrics.classification_report(
y_true,
y_pred,
,
labels=None,
target_names=None,
sample_weight=None,
digits=2,
output_dict=False,
zero_division='warn'
)Parameters:
y_true: Array of true labels.y_pred: Array of predicted labels.labels: (Optional) List of label indices to include in the report.target_names: (Optional) List of string names for the labels.sample_weight: (Optional) Array of weights for each sample.digits: Number of decimal places for formatting output.output_dict: IfTrue, return output as a dictionary.zero_division: Sets the behavior when there is a zero division (e.g., ‘warn’, 0, 1).
Metrics Explained
-
Precision: The ratio of correctly predicted positive observations to the total predicted positives. It indicates the quality of the positive class predictions.
-
Recall (Sensitivity): The ratio of correctly predicted positive observations to all actual positives. It measures the ability of a model to find all relevant cases.
-
F1 Score: The weighted average of precision and recall. It is a better measure than accuracy for imbalanced classes.
-
Support: The number of actual occurrences of the class in the specified dataset.
Resources
In ML_Tools see: Evaluation_Metrics.py