Recurrent Neural Networks (RNNs) are a type of neural network designed to process sequential data by maintaining a memory of previous inputs through hidden states. This makes them suitable for tasks where the order of data is needed, such as:
- Time Series prediction,
- speech recognition,
- and natural language processing (NLP).
RNNs have loops in their architecture, allowing information to persist across sequence steps. However, they face challenges with long sequences due to vanishing and exploding gradients problem. To address these issues, variants like Long Short-Term Memory (LSTM) and GRU (GRU) have been developed.
Resources:
Video link https://stanford.edu/~shervine/teaching/cs-230/cheatsheet-recurrent-neural-networks
Key Concepts of RNNs
Sequential Data Handling
- RNNs maintain a hidden state that acts as memory, enabling them to model temporal dependencies. This is essential for tasks where the current output depends on both current and previous inputs.
- At each time step, RNNs process an input, combine it with the previous hidden state, and produce an output along with an updated hidden state.
- The hidden state carries forward information influenced by all previous inputs, theoretically allowing RNNs to remember long-term dependencies.
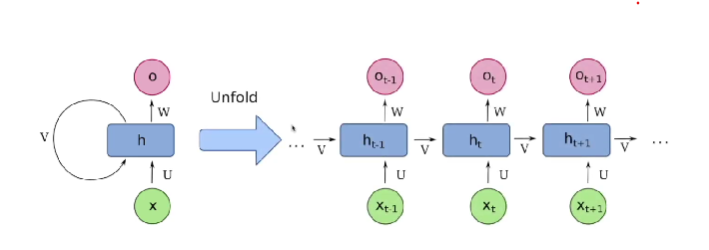
Backpropagation Through Time (BPTT)
- RNNs are trained using BPTT, a variant of backpropagation. The network unrolls over time, treating each time step as a layer in a deep network.
- Gradients are computed for each time step, and weights are updated based on cumulative error across the sequence. This allows learning of long-term dependencies but can lead to vanishing and exploding gradients in long sequences.
Variants of RNNs
- LSTM: Introduces gates (input, forget, output) to control information flow, addressing vanishing gradients and improving long-sequence handling.
- GRU: A simpler variant of LSTM with fewer parameters, offering efficiency and ease of training while maintaining performance on sequence tasks.
Example Code (RNN in Python with PyTorch)
See in ML_Toolssee: RNN_Pytorch.py
Problem of Long Term Dependencies
The more time steps we include the less data we keep from the past.
Solutions: LSTM and GRU: use gates: but are costly in computation.

Other areas
RNNS and Transformers
Why have Transformer’s have replaced traditional RNN.
Inductive Reasoning, Memories and Attention.
How to address the limitations of vanilla recurrent networks.
Issues:
- RNNs are not inductive: They memorize sequences extremely well, but don’t generalise well.
- They couple their representation size to the amount of computation per step.