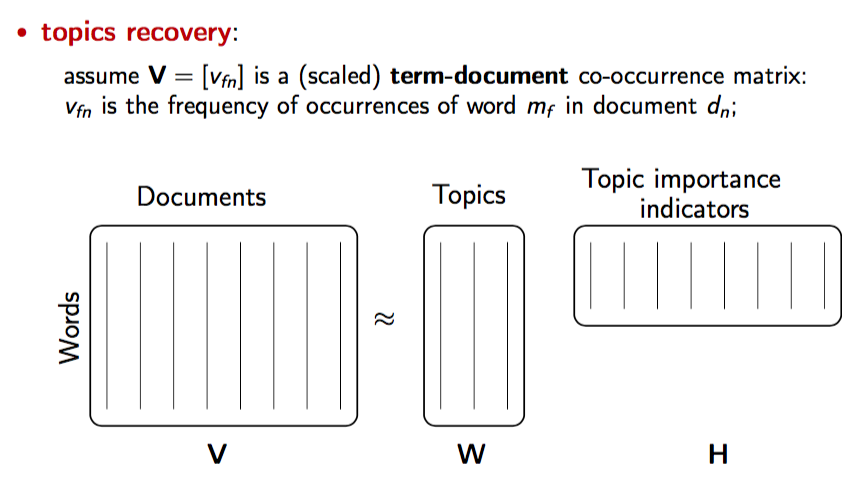
Non-negative Matrix Factorization (NMF) is a matrix decomposition technique that factors a non-negative matrix into two non-negative matrices and such that:
In NLP, NMF is often applied to document-term matrices for topic modeling and feature extraction.
How NMF Works in NLP
-
Construct a document-term matrix :
- Rows = documents
- Columns = terms/words
- Entries = term frequency (TF) or TF-IDF.
-
Decompose into:
- (document-topic matrix): Each row represents the distribution of topics for a document.
- (topic-term matrix): Each row represents the distribution of terms for a topic.
-
Interpret topics:
- Each topic is represented by a set of high-weight words from .
- Each document is represented by a mixture of topics from .
Application to Topic Importance Indicators
- Topic Importance for Documents: Look at to see which topics dominate a document.
- Key Words for Topics: Look at to find top terms per topic, which serve as indicators of the topic’s content or importance.
- Ranking Features: Terms with higher weights in are more important for defining a topic.
Benefits
- Produces interpretable topics because all entries are non-negative.
- Works well with sparse and high-dimensional NLP data.
- Can complement feature importance analysis in text classification and clustering.
Example (Python, using TF-IDF)
from sklearn.decomposition import NMF
from sklearn.feature_extraction.text import TfidfVectorizer
documents = ["I love NLP", "Machine learning is fun", "NLP and ML are related"]
vectorizer = TfidfVectorizer()
V = vectorizer.fit_transform(documents)
nmf = NMF(n_components=2, random_state=42)
W = nmf.fit_transform(V) # document-topic matrix
H = nmf.components_ # topic-term matrix- Rows of → important words per topic (topic indicators)
- Rows of → importance of topics per document
Image